학교 Alpha프로젝트를 위한 많은 AI 기능을 처리하기 위한 자연어처리 인공지능 모델을 만들기 위해
Pytorch, Tensorflow, 논문, flask, 각종 모델과 API 스터디를 했다.
스터디 결과 원하는 기능인 기술 스택 추천 기능, 코드 블럭 -> 텍스트기반 코드 변환 기능, Q&A 챗봇 기능을 구현 하려면 엄청난 데이터를 요구하는 대규모 언어 모델인 LLM이 필요하다고 느꼈다.
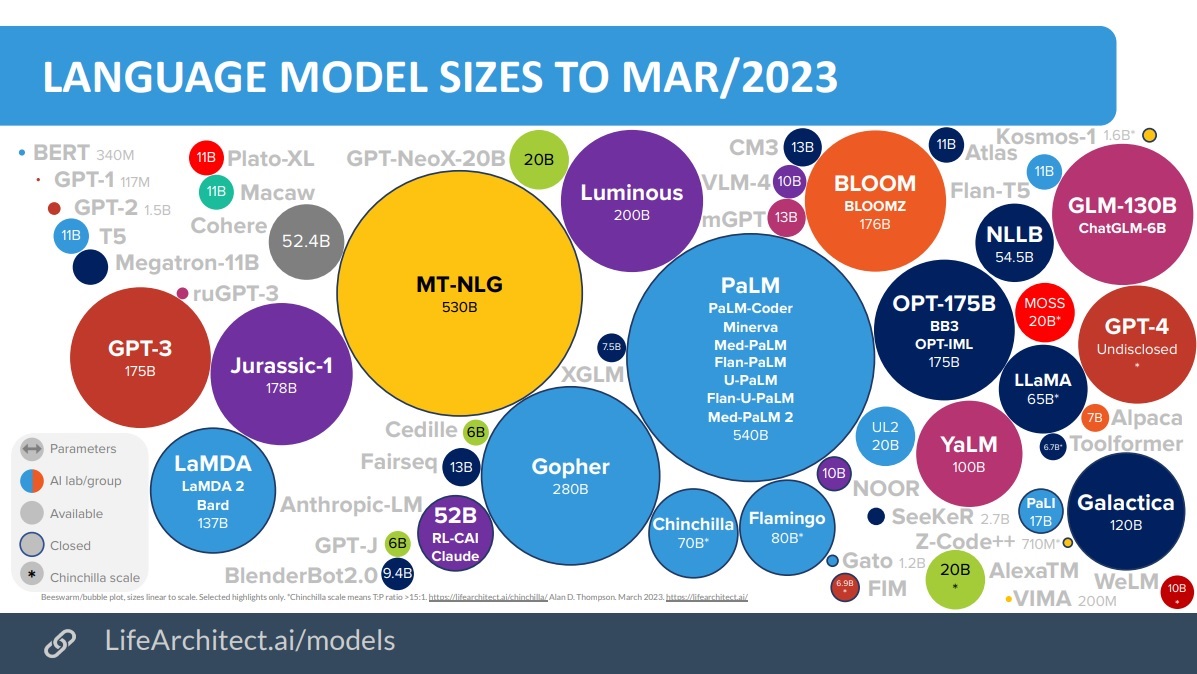
대규모 LLM 모델을 다루기전에 GPT-2, 3로 파인튜닝 코드를 작성해보면서 감을 잡았다.
가장 첫 번째로 해볼 것은 배포를 위한 Flask 스터디와 구현 방법 탐구이다.
OpenAI의 API 토큰을 받아온 뒤 작성한
Model2의 코드이다.
app.py
import openai
from flask import Flask, request, jsonify
app = Flask(__name__)
# OpenAI API 키 설정
openai.api_key = 'APIKEY'
@app.route('/chatbot', methods=['POST'])
def chatbot():
data = request.json
question = data.get('question', '')
try:
# GPT-3를 사용하여 질문에 대한 답변 생성
response = openai.Completion.create(
engine="text-davinci-003",
prompt=question,
temperature=0.7,
max_tokens=150,
top_p=1.0,
frequency_penalty=0.0,
presence_penalty=0.0
)
answer = response.choices[0].text.strip()
except Exception as e:
answer = f"죄송합니다, 오류가 발생했습니다: {str(e)}"
return jsonify({"answer": answer})
if __name__ == '__main__':
app.run(debug=True, port=5000)
모델 서빙을 위한 flask의 skeleton code 에 필요한 요구사항을
추가로 구현 하였다.
FineTunedModel.py
import openai
openai.api_key = 'APIKEY'
# 파인튜닝 파일 업로드
response = openai.File.create(file=open("finetune_data.jsonl"), purpose='fine-tune')
file_id = response['id']
# 파인튜닝 작업 제출
finetune_response = openai.FineTune.create(
training_file=file_id,
model="gpt-3.5-turbo",
n_epochs=1,
learning_rate_multiplier=0.1,
prompt_loss_weight=0.1,
)
print(f"파인튜닝 작업이 시작되었습니다. 작업 ID: {finetune_response['id']}")
finetune_id = finetune_response['id']
finetune_status = openai.FineTune.retrieve(id=finetune_id)
print(f"파인튜닝 작업 상태: {finetune_status['status']}")
OpenAI에서 GPT-2,3을 파인튜닝한 모델을 불러오고
파라미터 조정을 했다.
이제 모델 구현을 위한 데이터셋을 가져오는 과정과 데이터 처리를 해보자
데이터 처리 구현을 위한 라이브러리는 다음과 같다
import math
import numpy as np
import pandas as pd
import random
import re
import torch
import urllib.request
from torch.utils.data import DataLoader, Dataset
from transformers import PreTrainedTokenizerFast
import urllib.request
urllib.request.urlretrieve(
"https://raw.githubusercontent.com/songys/Chatbot_data/master/ChatbotData.csv",
filename="ChatBotData.csv",
)
Chatbot_Data = pd.read_csv("ChatBotData.csv")
# Test 용으로 300개 데이터만 처리한다.
Chatbot_Data = Chatbot_Data[:300]
Chatbot_Data.head()
BOS = "</s>"
EOS = "</s>"
PAD = "<pad>"
MASK = "<unused0>"
# 허깅페이스 transformers 에 등록된 사전 학습된 koGTP2 토크나이저를 가져온다.
koGPT2_TOKENIZER = PreTrainedTokenizerFast.from_pretrained
("skt/kogpt2-base-v2",
bos_token=BOS,
eos_token=EOS,
unk_token="<unk>",
pad_token=PAD,
mask_token=MASK,)
모델 테스트를 위한 데이터를 가져오기 위해
송영숙님의 챗봇 데이터 (https://github.com/songys/Chatbot_data)의 구조를 그대로 사용할 것이다.
데이터의 Q 필드를 발화, A 필드를 발화 그리고 감정 레이블을 사용합니다. 감정 레이블은 label에 정의된 일상다반사 0, 이별(부정) 1, 사랑(긍정) 2)를 그대로 적용한다.
이제 데이터셋을 정의 해보자
# 챗봇 데이터를 처리하는 클래스를 만든다.
class ChatbotDataset(Dataset):
def __init__(self, chats, max_len=40):
Q_TKN = "<usr>"
A_TKN = "<sys>"
SENT = '<unused1>'
# 데이터셋의 전처리를 해주는 부분
self._data = chats
self.max_len = max_len
self.q_token = Q_TKN
self.a_token = A_TKN
self.sent_token = SENT
self.eos = EOS
self.mask = MASK
self.tokenizer = koGPT2_TOKENIZER
def __len__(self): # chatbotdata 의 길이를 리턴한다.
return len(self._data)
def __getitem__(self, idx): # 로드한 챗봇 데이터를 차례차례 DataLoader로 넘겨주는 메서드
turn = self._data.iloc[idx]
q = turn["Q"] # 질문을 가져온다.
q = re.sub(r"([?.!,])", r" ", q) # 구둣점들을 제거한다.
a = turn["A"] # 답변을 가져온다.
a = re.sub(r"([?.!,])", r" ", a) # 구둣점들을 제거한다.
q_toked = self.tokenizer.tokenize(self.q_token + q + self.sent_token)
q_len = len(q_toked)
a_toked = self.tokenizer.tokenize(self.a_token + a + self.eos)
a_len = len(a_toked)
#질문의 길이가 최대길이보다 크면
if q_len > self.max_len:
a_len = self.max_len - q_len #답변의 길이를 최대길이 - 질문길이
if a_len <= 0: #질문의 길이가 너무 길어 질문만으로 최대 길이를 초과 한다면
q_toked = q_toked[-(int(self.max_len / 2)) :] #질문길이를 최대길이의 반으로
q_len = len(q_toked)
a_len = self.max_len - q_len #답변의 길이를 최대길이 - 질문길이
a_toked = a_toked[:a_len]
a_len = len(a_toked)
#질문의 길이 + 답변의 길이가 최대길이보다 크면
if q_len + a_len > self.max_len:
a_len = self.max_len - q_len #답변의 길이를 최대길이 - 질문길이
if a_len <= 0: #질문의 길이가 너무 길어 질문만으로 최대 길이를 초과 한다면
q_toked = q_toked[-(int(self.max_len / 2)) :] #질문길이를 최대길이의 반으로
q_len = len(q_toked)
a_len = self.max_len - q_len #답변의 길이를 최대길이 - 질문길이
a_toked = a_toked[:a_len]
a_len = len(a_toked)
# 답변 labels = [mask, mask, ...., mask, ..., <bos>,..답변.. <eos>, <pad>....]
labels = [self.mask,] * q_len + a_toked[1:]
# mask = 질문길이 0 + 답변길이 1 + 나머지 0
mask = [0] * q_len + [1] * a_len + [0] * (self.max_len - q_len - a_len)
# 답변 labels을 index 로 만든다.
labels_ids = self.tokenizer.convert_tokens_to_ids(labels)
# 최대길이만큼 PADDING
while len(labels_ids) < self.max_len:
labels_ids += [self.tokenizer.pad_token_id]
# 질문 + 답변을 index 로 만든다.
token_ids = self.tokenizer.convert_tokens_to_ids(q_toked + a_toked)
# 최대길이만큼 PADDING
while len(token_ids) < self.max_len:
token_ids += [self.tokenizer.pad_token_id]
#질문+답변, 마스크, 답변
return (token_ids, np.array(mask), labels_ids)
리턴되는 데이터는 token_ids, mask, labels_ids 이다. token_ids 는 + 질문문장 + + 감정 + + 답변 + + pad_token_id 순서. pad_token_id는 max_len 에 일치하도록 추가 된다. mask 는 질문 q가 들어 가는 곳에는 0, 답변 a가 위치한 곳에는 1 그리고 빈 공간에는 0 으로 채워 진다. labels은 질문의 길이만큼 mask 문자 그리고 답변 a의 id 이다.
배치 데이터를 만들어 보자
def collate_batch(batch):
data = [item[0] for item in batch]
mask = [item[1] for item in batch]
label = [item[2] for item in batch]
return torch.LongTensor(data), torch.LongTensor(mask), torch.LongTensor(label)
데이터셋과 DataLoader를 정의 후 데이터로더를 사용해서 데이터를 생성해보자
train_set = ChatbotDataset(Chatbot_Data, max_len=40)
#윈도우 환경에서 num_workers 는 무조건 0으로 지정, 리눅스에서는 2
train_dataloader = DataLoader(train_set, batch_size=32, num_workers=0, shuffle=True, collate_fn=collate_batch,)
print("start")
for batch_idx, samples in enumerate(train_dataloader):
token_ids, mask, label = samples
print("token_ids ====> ", token_ids)
print("mask =====> ", mask)
print("label =====> ", label)
print("end")
...오늘은 Dataset, DataLoader 기능 테스트를 진행하고 데이터처리 해보았다 다음엔 모델 구현을 해보자
'NLP' 카테고리의 다른 글
| RNN 사용해서 감정 분석 해보기 (0) | 2024.06.20 |
|---|---|
| BERT로 감정 분석 실습 해보기 (30) | 2024.06.20 |
| Transformer로 간단한 챗봇 구현 및 평가 해보기 (2) | 2024.05.02 |
| Transformer 데이터 전처리 해보기 (5) | 2024.05.01 |
| Transfomer는 무엇일까? + 포지셔널 인코딩 간단 구현 해보기 (2) | 2024.03.30 |



