[논문리뷰] Co-teaching: Robust Training of Deep Neural Networks with Extremely Noisy
지능형 컴퓨터 비전 랩실에서 학부연구생 활동을 시작하고 교수님과 미팅 결과,
현재 Vision 쪽 관심 분야인 Remote sensing image, satelite image deep learning 탐구를 위해 Data labeling, Denoising 쪽 논문을 쭉 읽어보기로 하였다.
논문: “Co-teaching: Robust Training of Deep Neural Networks with Extremely Noisy Labels”
이 논문은 딥러닝 모델이 매우 노이즈가 많은 라벨 환경에서도 견고하게 학습할 수 있도록 새로운 학습 패러다임인 Co-teaching을 소개한다.
배경과 문제 인식
딥러닝 모델은 높은 학습 용량을 가지고 있어, 결국 노이즈가 있는 라벨까지 암기하게 된다. 이는 모델의 generalization 성능을 크게 저하시킨다. 논문에서는 이러한 문제를 해결하기 위해 Co-teaching이라는 기법을 제안한다. Co-teaching은 두 개의 신경망을 동시에 학습시키고, 각 신경망이 작은 손실을 가진 인스턴스(즉, 더 깨끗한 라벨을 가진 데이터)를 서로 선택해 학습을 돕는 방식으로 작동한다.
Co-teaching 알고리즘:
Co-teaching Algorithm은 매우 노이즈가 많은 라벨 환경에서도 딥러닝 모델이 견고하게 학습할 수 있도록 설계된 알고리즘이다. 이 알고리즘은 두 개의 신경망을 동시에 학습시키고, 각 네트워크가 자신만의 기준에 따라 노이즈가 적을 가능성이 높은 데이터를 선택해 상대방 네트워크에 전달함으로써, 서로가 노이즈에 민감한 부분을 교정해주는 방식으로 작동한다.
Co-teaching 알고리즘의 주요 구성 요소
1. 두 개의 네트워크 훈련:
Co-teaching 알고리즘은 두 개의 신경망을 동시에 훈련시킨다. 이 네트워크들은 동일한 구조를 가지지만, 서로 다른 initialized 값으로 시작한다. 이로 인해 두 네트워크는 같은 데이터셋을 학습하더라도 각기 다른 방식으로 데이터 패턴을 학습할 수 있게 되며, 이는 서로가 다른 라벨 노이즈에 대해 더 잘 대처할 수 있다.
2. Small-Loss Instance Selection:
각 네트워크는 미니 배치 데이터를 기반으로 작은 손실을 가진 인스턴스를 선택한다. 논문에서는 신경망이 먼저 깨끗한 데이터를 학습하고, 점차 노이즈가 있는 데이터를 학습하는 특성을 이용한다. 즉, 작은 손실을 가진 인스턴스일수록 그 데이터의 라벨이 깨끗할 가능성이 크다는 가정하에, 각 네트워크는 이러한 인스턴스들을 선택.
3. Cross Update:
각 네트워크는 자신이 선택한 small-loss 인스턴스를 상대방 네트워크에 전달한다. 예를 들어, 네트워크 A는 자신이 선택한 small-loss 데이터를 네트워크 에 전달하여 B가 학습하게 하고, 역시 자신의 small-loss 데이터를 A에 전달해 학습하게 한다. 이 방식은 두 네트워크가 서로 다른 방식으로 노이즈를 걸러내고, 각각의 네트워크가 스스로의 오류를 축적하는 것을 방지하는 역할을 한다.
4. Dynamic Instance Drop Rate:
학습 초반에는 신경망이 깨끗한 데이터를 빠르게 학습하기 때문에 모든 데이터를 사용해 학습을 시작한다. 시간이 지나면서 노이즈가 있는 데이터까지 학습할 가능성이 커지기 때문에, R(T)라는 함수에 따라 점차적으로 더 많은 noisy 인스턴스를 걸러낸다. R(T)는 학습이 진행됨에 따라 감소하는 비율을 결정하며, 값이 클수록 더 많은 데이터를 유지하고, 작아질수록 더 많은 noisy 데이터를 걸러내는 방식으로 동작한다.
Co-teaching 알고리즘의 동작 과정 (세부 설명)

• Step 1: 두 네트워크를 초기화하고, 학습률 , 드롭 비율 등 필요한 하이퍼파라미터를 설정한다.
• Step 2: 훈련 데이터셋을 섞은 후, 미니 배치 를 가져온다.
• Step 3: 각 네트워크는 손실이 작은 인스턴스 각각 선택한다. 여기서 각 네트워크는 미니 배치 내에서 자신만의 small-loss 인스턴스를 선택해 노이즈가 적을 것으로 추정되는 데이터를 고른다.
• Step 4: 각 네트워크는 선택된 인스턴스를 사용해 상대방 네트워크의 가중치를 업데이트한다. 즉, A는 B의small-loss 인스턴스를 학습하고, B는 A의 small-loss 인스턴스를 학습한다.
• Step 5: 학습이 진행됨에 따라, 드롭 비율은 점차 증가하여 더 많은 noisy 데이터를 걸러낸다.
• Step 6: 최대 학습 단계 까지 반복한 후 최종 네트워크 파라미터 와 를 반환한다.
이 알고리즘의 두 가지 핵심 포인트가 존재 한다.
1. 왜 Small-loss 인스턴스가 노이즈가 적은 데이터를 찾아내는 데 도움이 될까?
신경망은 초기 학습 단계에서 상대적으로 깨끗한 데이터를 먼저 학습하는 경향이 있다. 손실이 작은 인스턴스는 더 깨끗한 라벨을 가질 가능성이 높기 때문에, 이러한 인스턴스를 선택해 학습하면 노이즈가 있는 라벨의 영향을 최소화할 수 있다.
2. 왜 두 개의 Network를 사용하고, 서로 Cross 업데이트를 하는가?
단일 네트워크로 학습을 진행할 경우, 잘못 선택된 noisy 데이터가 누적되면서 전체 학습 성능에 악영향을 미칠 수 있다. 하지만 두 네트워크가 교차 업데이트를 진행하면, 서로 다른 네트워크가 서로의 오류를 교정할 수 있다. 이 방식은 Co-training 방법에서 착안된 것으로, Co-teaching은 노이즈 라벨 학습에 맞춰진 방식이다.
기존 방법과 비교 해보자
논문에서는 MentorNet, Decoupling, Bootstrap, S-model, F-correction 등의 기존 방법들과 Co-teaching을 비교한다.
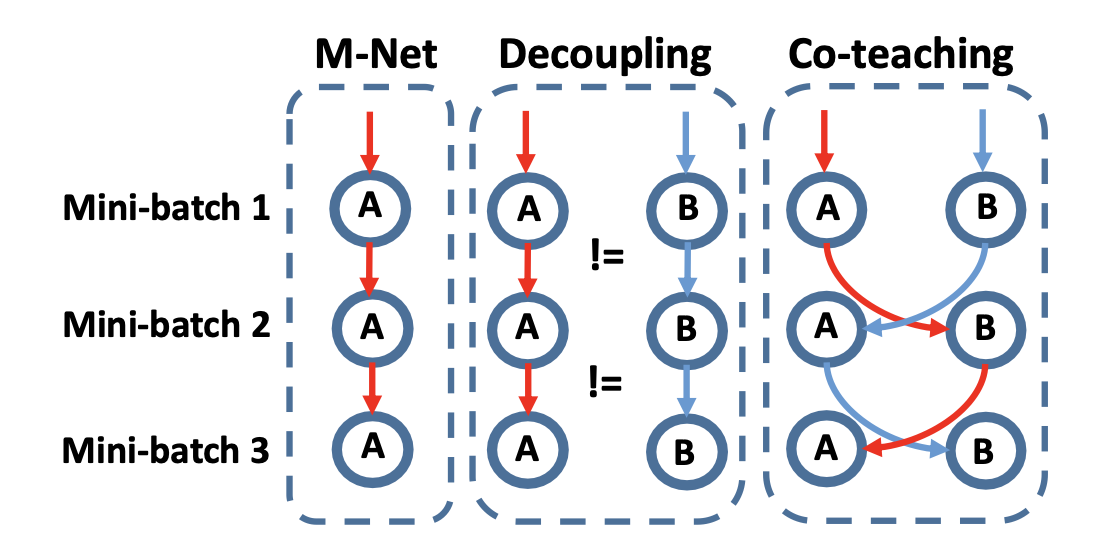
MentorNet, Decoupling, Bootstrap, S-model, F-correction 같은 대표적인 노이즈 라벨 처리 방법들과 비교하면서, Co-teaching이 더 나은 성능을 보이는 이유를 알아보자:
MentorNet은 teacher-student 구조를 기반으로 한 방식이다. 여기서 teacher network는 사전에 훈련되어 학습 중 student network가 사용할 깨끗한 데이터를 선택한다. Teacher network가 사전 훈련을 통해 clean 데이터를 골라내기 때문에, 노이즈가 적은 데이터를 학습하도록 돕는다. 하지만 MentorNet은 추가적인 네트워크를 사전 훈련해야 하며, 사전 학습된 teacher network의 성능에 따라 전체 성능이 좌우될 수 있다는 한계가 있다.
Co-teaching은 사전 학습된 네트워크 없이, 학습 도중 두 네트워크가 서로 small-loss 데이터를 교환하며 학습하기 때문에, 더 유연하며 사전 훈련이 필요하지 않다. Co-teaching은 두 네트워크가 서로 상호 보완적인 방식으로 노이즈 데이터를 걸러내며, 더 나은 견고성을 보인다.
Decoupling은 두 개의 신경망을 동시에 훈련하고, 두 네트워크가 서로 다른 예측을 내리는 경우에만 해당 데이터를 사용하여 학습하는 방식이다. 이 방법은 노이즈가 퍼져 있는 데이터셋에서 일부 노이즈를 걸러낼 수 있지만, 두 네트워크가 예측이 다를 때만 업데이트를 수행하기 때문에, 특히 심한 노이즈 환경에서는 성능이 떨어질 수 있다. Decoupling은 네트워크가 불일치한 예측을 하는 영역에서만 작동하기 때문에, 노이즈가 데이터 전체에 고르게 퍼져 있을 때 효과적이지 않다.
반면 Co-teaching은 두 네트워크가 서로의 small-loss 데이터를 교환하여 업데이트하기 때문에, 두 네트워크의 예측이 동일하더라도 노이즈 데이터를 걸러내는 데 효과적이다. 실험 결과, Co-teaching은 Decoupling보다 더 높은 정확도를 보여주며, 특히 노이즈가 심한 환경에서 우수한 성능을 나타낸다.
Bootstrap은 Label Bootstrapping 방식으로, 모델의 예측값과 원래의 노이즈 라벨을 결합하여 새로운 라벨을 생성하고, 이 새로운 라벨을 사용해 학습하는 방식이다. 하지만 Bootstrap은 잘못된 예측이나 노이즈 라벨을 기반으로 학습을 진행할 경우 그 오차가 누적될 수 있으며, 노이즈 비율이 높은 경우 성능이 크게 저하될 수 있다.
S-model은 노이즈 전이 행렬(Noise Transition Matrix)을 학습하는 방식이다. 이 방식은 노이즈가 포함된 라벨에서 실제 라벨로 전이되는 확률을 학습하여 모델이 노이즈를 처리할 수 있도록 돕는다. 하지만 이 전이 행렬을 정확하게 추정하는 것이 어려운 문제이며, 특히 클래스의 수가 많거나 노이즈가 심할 경우 성능이 떨어질 수 있다.
Co-teaching은 기존 방법들과 비교했을 때, 다음과 같은 여러 장점을 가진다:
• 두 네트워크의 상호 보완성: 두 개의 신경망이 서로의 small-loss 데이터를 교환하여 학습함으로써, 단일 네트워크보다 더 효과적으로 노이즈를 걸러낼 수 있다.
• Pre-train No need: Co-teaching은 사전 학습이 필요하지 않으며, 학습 도중에 두 네트워크가 상호 보완적으로 노이즈를 처리한다.
• 노이즈 처리 능력: 노이즈 전이 행렬을 추정할 필요가 없으며, 심한 노이즈 환경에서도 기존 방법들보다 뛰어난 성능을 보인다.
실험 결과에서도, Co-teaching은 MentorNet, Decoupling, Bootstrap, S-model, F-correction과 비교하여 더 높은 정확도를 나타내며, 특히 노이즈 비율이 높은 상황에서 그 우수성이 두드러진다.
실험 결과
논문에서는 MNIST, CIFAR-10, CIFAR-100 같은 데이터셋에 대해 Co-teaching 알고리즘을 적용해 실험을 진행한다. 이들 데이터셋에 인위적으로 노이즈를 추가한 후 성능을 비교한 결과, Co-teaching이 기존의 다른 방법들보다 훨씬 뛰어난 성능을 보였다. 특히, 노이즈가 45% 이상인 환경에서도 높은 정확도를 유지하며, MentorNet보다 더 나은 성능을 나타냈다.
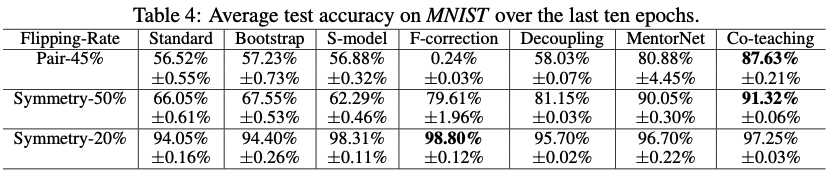
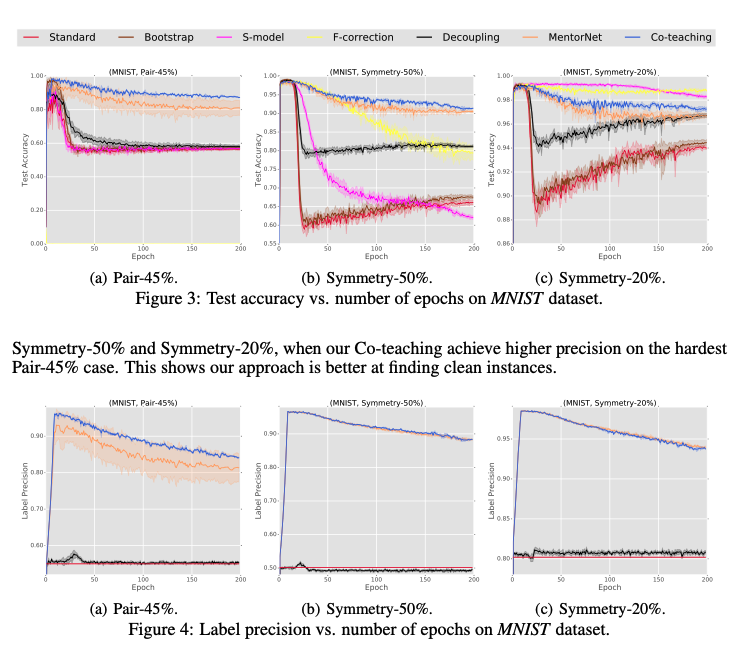
1. MNIST 데이터셋에서 Co-teaching은 노이즈가 50% 이상인 경우에도 90% 이상의 정확도를 달성했으며, Symmetry와 Pair 노이즈 시나리오에서 모두 우수한 성능을 보였다.
2. CIFAR-10 및 CIFAR-100에서도, 특히 노이즈가 심한 경우(Co-teaching에서는 45% 노이즈가 있는 환경에서도 정확도 72.62%)에서 다른 방법들보다 훨씬 우수한 성능을 보였다.
...다음에는 ICML - SELFIE 논문리뷰를 해보겠다